
Our team has worked on source detection and classification. These methods have been applied to 2D continuum radio maps that were the object of the first SKA data challenge (SDC1). We have also participated to the second SKA data challenge (SDC2) which goal was to identify sources in a simulated SKA data cube.
The MINERVA team is the winner of the second SKA data challenge
SKA data challenge 2 : link to leaderboard with updated scores
The SKAO SDC2 summary paper has been published in MNRAS and is available here.

Team Minerva


Method description
the YOLO-CHADHOC pipeline
The MINERVA team approached the SDC2 by developing from scratch two end-to-end pipelines in parallel. The final catalogue merges the results from the two pipelines.
YOLO-CIANNA
For the purpose of the SDC2 we implemented a highly customised version of a YOLO (You Only Look Once, Redmon et al. 2015) network which is a regression based Convolutional Neural Network dedicated to object detection and classification. To train our network we added low level YOLO capabilities in our own general purpose CNN framework CIANNA Github (Convolutional Interactive Artificial Neural Networks by/for Astrophysicists) which is CUDA GPU accelerated. The method is fully described for 2D images in Cornu et al. 2024.
Our custom YOLO network works on sub-volumes of 64x64x256 (RA, Dec, Freq) pixels and performs detection based on a sub-grid of size 8x8x16. Each grid element (sub-cube of 8x8x16 pixels) can be associated to a candidate detection with the following parameters: x, y, z the object position inside the sub grid element; w, h, d the « box » dimension in which the object is inscribed; and O an objectness score. We also modified the YOLO loss to predict the source parameters: Flux, HIsize, w20, PA and I at the same time for each box.
Our YOLO network is made of 21 (3D)-convolutional layers which alternate several « large » filters (usually 3x3x5) that extract morphological properties and fewer « smaller » filters (usually 1x1x3) that force a higher degree feature space and allow to preserve a manageable number of weights to optimise. Some of the layers also include a higher stride value in order to progressively reduce the dimension down to the 8x8x16 grid and the few last layers include dropout for regularisation and error estimation. The network was trained by selecting either: a sub-volume that contains a true source (at least); or a random empty field to learn to exclude all types of noise aggregation and artifacts. All inputs where augmented using position and frequency offset as well as flips. The trained network has an inference speed of 70 input cubes (64x64x256) per second using a V100 GPU on Jean-Zay/IDRIS, but due to necessary partial overlap and to RAM limitations, it still requires up to 25 GPU hours to get the complete prediction on the full ~1TB data cube.

CHADHOC
The Convolutional Hybrid Ad-Hoc pipeline (CHADHOC) is composed of three steps: a simple detection algorithm, a Convolutional Neural Network (CNN) for identifying true sources among the detections, and individual CNNs for each source parameter estimation.
The detection step
For detection, a traditional algorithm is used. The signal cube is first pre-processed by smoothing along the frequency dimension (600 kHz width). Then the signal is converted to a signal-to-noise ratio on a per channel basis. Pixels below a fixed S/N ratio are filtered out, and the remaining pixels are aggregated into a catalogue of sources.
The selection step
This step is performed with a CNN. A learning sample is built by cross-matching the 10⁵ brightest detections in the development cube with the truth catalogue, thus assigning a True/False label to each detection. Cutouts of 38x38x100 pixels (frequency last) around the position of each detection are the inputs for the network. A test set is isolated made of one third of the detections. The comparatively light network is made of 5 3D-convolutional layers, 3 dense layers and regularization layers. In total the network has of the order of 10⁵ parameters. For each detection, the output is not a simple True/False statement but a number between 0. (False) and 1. (True).
Parameter estimation
A distinct CNN has been developed to predict each of the sources parameters. The architecture is similar to the one of the CNN for sources selection.
Cutouts around the ~1300 brightest sources in the truth catalogue of the development cube are augmented by flipping and used to build the learning and tests sets.
Many small things impact the final performance of the pipeline. Among them, the centering of the sources in the cutouts. Translational invariance is not trained into the networks. This is possibly the main limitation of the pipeline.
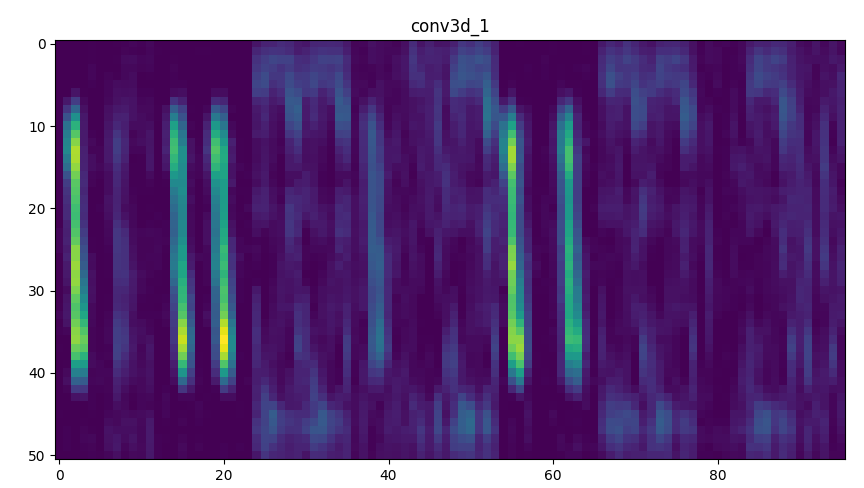
selection network for a bright source input.
Merging the catalogues
If we visualize the catalogues produced by YOLO and CHADHOC in the sources parameter space we see that they occupy slightly different regions. For example, CHADHOC tend to find a (slightly) larger number of typical sources compared to YOLO, but missed more low-brightness sources. Thus carefully merging the catalogue to improve completeness and purity yields a better final catalogue.
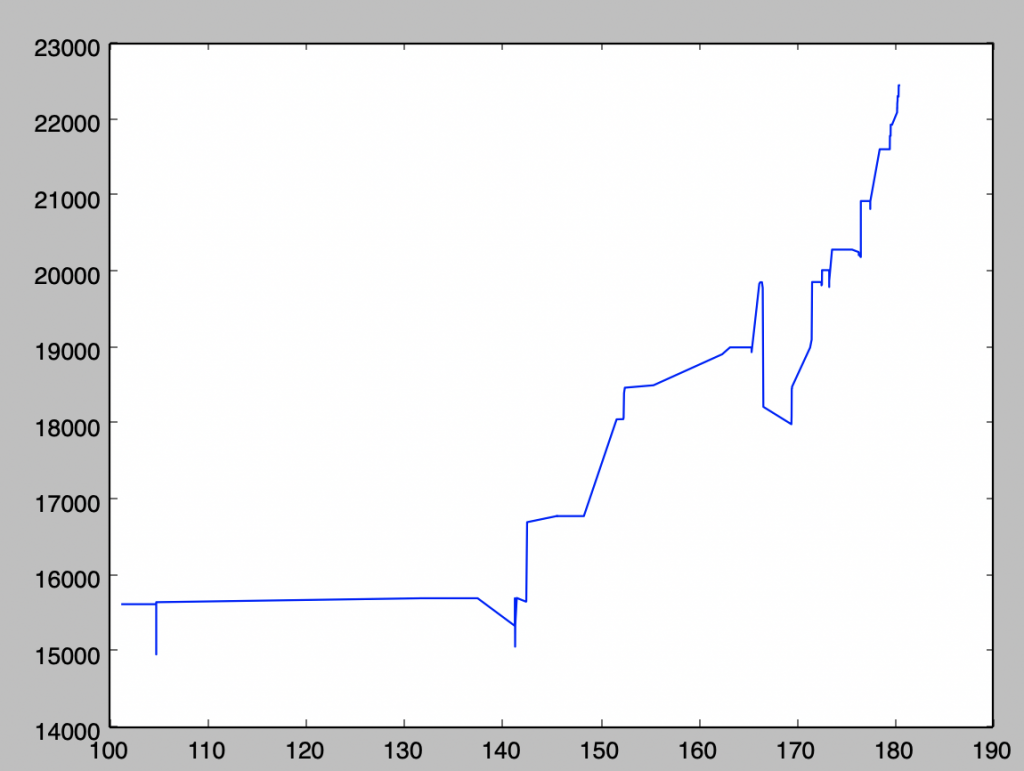
(days since the start of the challenge)
Resources

Context